多线程及其性能刻画
使用多线程提高并行性
同步的代价
我们研究对一列整数 $0, …, n - 1$ 求和,我们将序列划分成 $t$ 个不相交的的区域,给 $t$ 个线程每个分配一个区域。将线程的和放入一个变量中,并且我们使用互斥锁来保护这个变量。
use std::{
sync::{Arc, Mutex},
thread,
time::Instant,
};
fn main() {
let args = std::env::args().collect::<Vec<String>>();
if args.len() != 3 {
panic!("Usage: {} <nthreads> <log_nelems>", args[0]);
}
let nthreads: usize = args[1].parse().unwrap();
let log_nelems: usize = args[2].parse().unwrap();
let nelems = 1_usize << log_nelems;
let nelems_per_thread = nelems / nthreads;
let gsum = Arc::new(Mutex::new(0));
let now = Instant::now();
let mut handlers = vec![];
for i in 0..nthreads {
let gsum = Arc::clone(&gsum);
let handler = thread::spawn(move || {
let start = i * nelems_per_thread;
let end = start + nelems_per_thread;
for j in start..end {
let mut sum = gsum.lock().unwrap();
*sum += j;
}
});
handlers.push(handler);
}
for handle in handlers {
handle.join().unwrap();
}
assert_eq!(nelems * (nelems - 1) / 2, *gsum.lock().unwrap());
println!("Running took {} s.", now.elapsed().as_secs())
}
我们在一个四核系统上,对一个大小为 $n=2^{20}$ 的序列进行测试,运算时间以毫秒为单位,结果如下:
| 线程数 | 1 | 2 | 4 | 8 | 16 | 32 |
| 时间 | 14932 | 72823 | 76478 | 118155 | 108878 | 101532 |
结果令人难以理解,使用的CPU核数越多,性能越差。造成性能差的原因是相对于内存更新操作的开销,同步操作代价太大(P和V)。这突显了并行编程的一个重要教训:同步开销巨大,要尽可能避免。如果无法避免,必须要用尽可能多的有用计算弥补这个开销。
用局部变量优化,消除同步
因此,我们使用局部变量来消除不必要的内存引用,将每个对等线程把它的部分和累积在一个局部变量而不是全局变量中。
use std::{thread, time::Instant};
fn main() {
let args = std::env::args().collect::<Vec<String>>();
if args.len() != 3 {
panic!("Usage: {} <nthreads> <log_nelems>", args[0]);
}
let nthreads: usize = args[1].parse().unwrap();
let log_nelems: usize = args[2].parse().unwrap();
let nelems = 1_usize << log_nelems;
let nelems_per_thread = nelems / nthreads;
let now = Instant::now();
let mut handlers = vec![];
for i in 0..nthreads {
let handler = thread::spawn(move || {
let mut sum = 0;
let start = i * nelems_per_thread;
let end = start + nelems_per_thread;
for j in start..end {
sum += j;
}
sum
});
handlers.push(handler);
}
let mut gsum = 0;
for handle in handlers {
gsum += handle.join().unwrap();
}
assert_eq!(nelems * (nelems - 1) / 2, gsum);
println!("Running took {} s.", now.elapsed().as_micros() as f64 / 1e6)
}
我们在一个四核系统上,对一个大小为 $n=2^{31}$ 的序列进行测试,运算时间以秒为单位,结果如下:
| 线程数 | 1 | 2 | 4 | 8 | 16 | 32 |
| 时间 | 22.413 | 11.430 | 6.087 | 7.414 | 7.428 | 7.411 |
结果基本符合预期,得到一组递减的运行时间。
刻画并行程序的性能
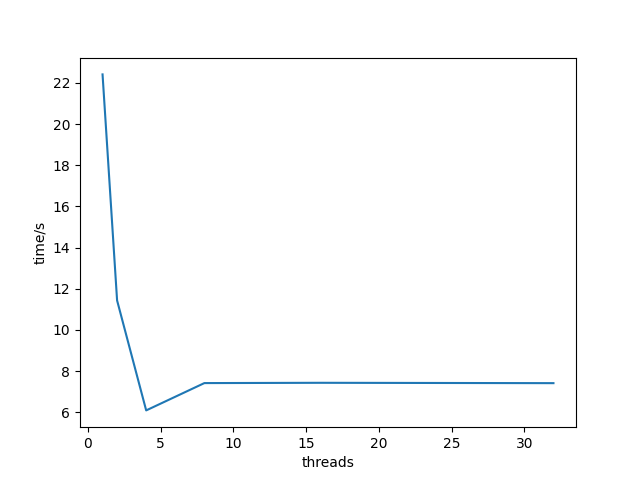
如图,我们看到,随着线程数的增加,运行时间下降,直到增加到四个线程,此时,运行时间趋于平稳,甚至开始有点增加。在理想的情况中,我们会期望运行时间随着核数的增加线性下降。也就是说,我们会期望线程数每增加一倍,运行时间就下降一半。确实是这样,直到到达 $t > 4$ 的时候,此时四个核中的每一个都忙于运行至少一个线程。随着线程数量的增加,运行时间实际上增加了一点儿,这是由于在一个核上多个线程上下文切换的开销。由于这个原因,并行程序常常被写为每个核上只运行一个线程。
虽然绝对运行时间是衡量程序性能的终极标准,但是还是有一些有用的相对衡量标准能够说明并行程序有多好的利用了潜在的并行性。并行程序的加速比通常定义为: $$ S_p = \frac{T_1}{T_p} $$ $p$ 是处理器核的数量, $T_k$ 是在 $k$ 个核上的运行时间。这个公式有时被称为强扩展(strong scaling)。当 $T_1$ 是程序顺序执行版本的执行时间时, $S_p$ 称为绝对加速比(absolute speedup)。绝对加速比比相对加速比能更真实地衡量并行的好处。即使是当并行程序在一个处理器上运行时,也常常会受到同步开销的影响,而这些开销会人为地增加相对加速比的数值,因为它们增加了分子的大小。另一方面,绝对加速比比相对加速比更难以测量,因为测量绝对加速比需要程序的两种不同的版本。对于复杂的并行代码,创建一个独立的顺序版本可能不太实际,或者因为代码太复杂,或者因为源代码不可得。
一种相关的测量量称为效率(efficiency),定义为: $$ E_p = \frac{S_p}{p} = \frac{T_1}{pT_p} $$通常表示为范围在 $(0, 100]$ 之间的百分比。效率是对由于并行化造成的开销的衡量。具有高效率的程序比效率低的程序在有用的工作上花费更多的时间,在同步和通信上花费更少的时间。
下表给出了我们并行求和示例程序的各个加速比和效率测量值。像这样超过 $90%$ 的效率是非常好的,但是不要被欺骗了。能取得这么高的效率是因为我们的问题非常容易并行化。在实际中,很少会这样。数十年来,并行编程一直是一个很活跃的研究领域。随着商用多核机器的出现,这些机器的核数每几年就翻一番,并行编程会继续是一个深入、困难而活跃的研究领域。
| 线程($t$) | $1$ | $2$ | $4$ | $8$ | $16$ | $32$ |
| 核($p$) | $1$ | $2$ | $4$ | $8$ | $16$ | $32$ |
| 运行时间( $T_p$ ) | $22.413$ | $11.430$ | $6.087$ | $7.414$ | $7.428$ | $7.411$ |
| 加速比( $S_p$ ) | $1$ | $1.96$ | $3.68$ | $3.023$ | $3.017$ | $3.024$ |
| 效率( $E_p$ ) | $100\%$ | $98\%$ | $92\%$ | $76\%$ | $75\%$ | $76\%$ |