Cloudflare事故报告(中文翻译)
引入
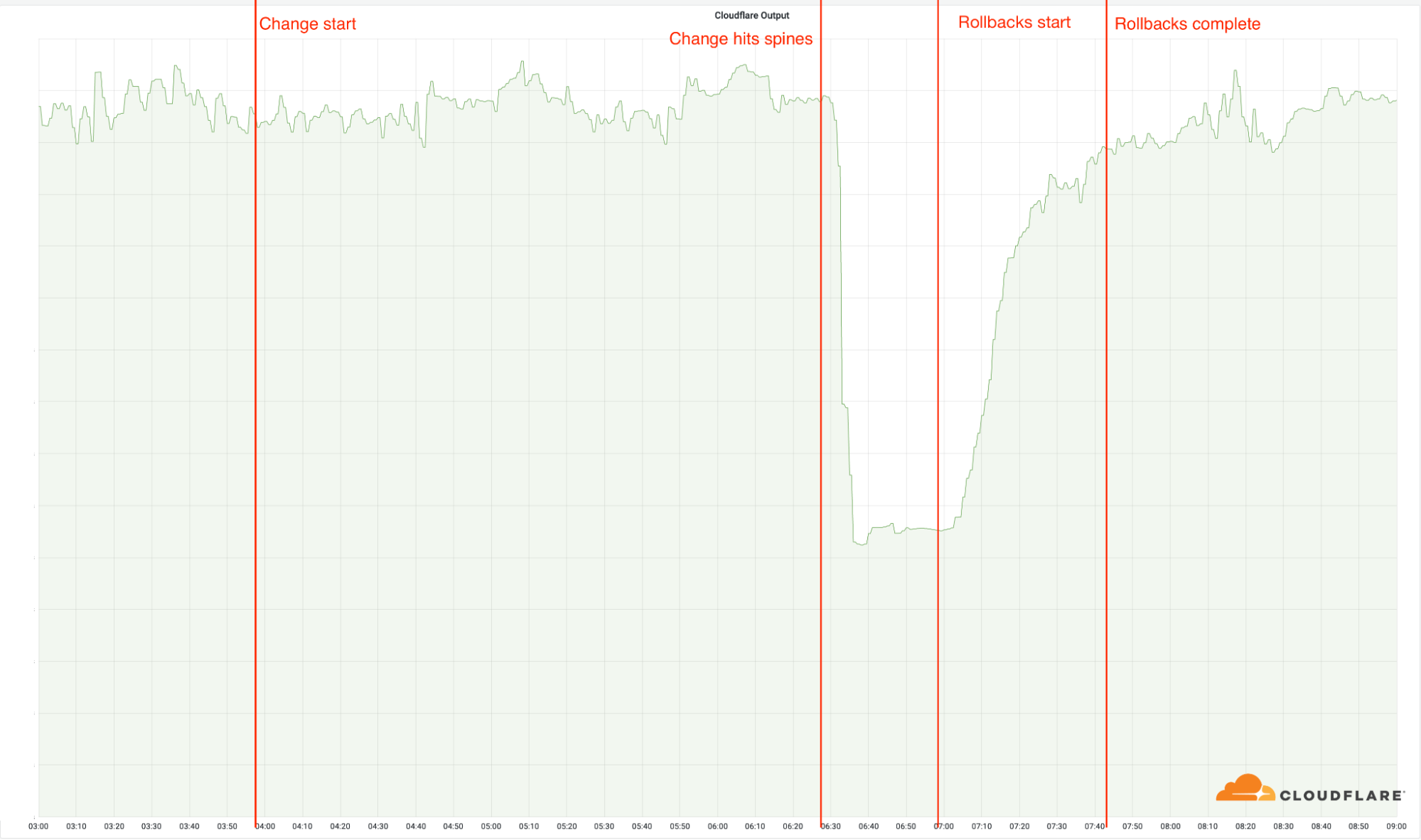
今天(2022年6月21日),Cloudflare发生故障,影响了我们19个数据中心的流量。不幸的是,这19个地点负责处理我们全球流量的很大一部分。这次故障是由一个变化引起的,这个变化是一个长期项目的一部分,该项目是为了提升我们最繁忙数据中心的可恢复能力。对这些数据中心网络配置的改变造成了从06:27(UTC)开始的宕机。在06:58(UTC),第一个数据中心重新上线,到07:42(UTC),所有的数据中心都上线并恢复了正常工作。
根据你所在的位置,你可能已经午饭访问依赖Cloudflare的网站和服务。在其他地方,Cloudflare继续正常运行。
我们对这次事故感到非常抱歉。这是我们自己的错误,并不是被攻击或恶意行为的结果。
背景
在过去的18个月里,Cloudflare一直在努力将我们所有最繁忙的地点转换为更灵活、更具弹性的架构。在这段时间里,我们已经将19个数据中心转为这种架构,在内部称为Multi-Colo PoP(MCP):阿姆斯特丹、亚特兰大、阿什本、芝加哥、法兰克福、伦敦、洛杉矶、马德里、曼彻斯特、迈阿密、米兰、孟买、纽瓦克、大阪、圣保罗、圣何塞、新加坡、悉尼、东京。
这个新架构的一个关键部分是一个附加的路由层,它被设计为一个Close Network,形成了一个网状的连接。这个网状结构使我们能够很容易地禁用或启用数据中心地部分内部网络,以便进行维护或处理问题。这一层如下图中的spines表示。
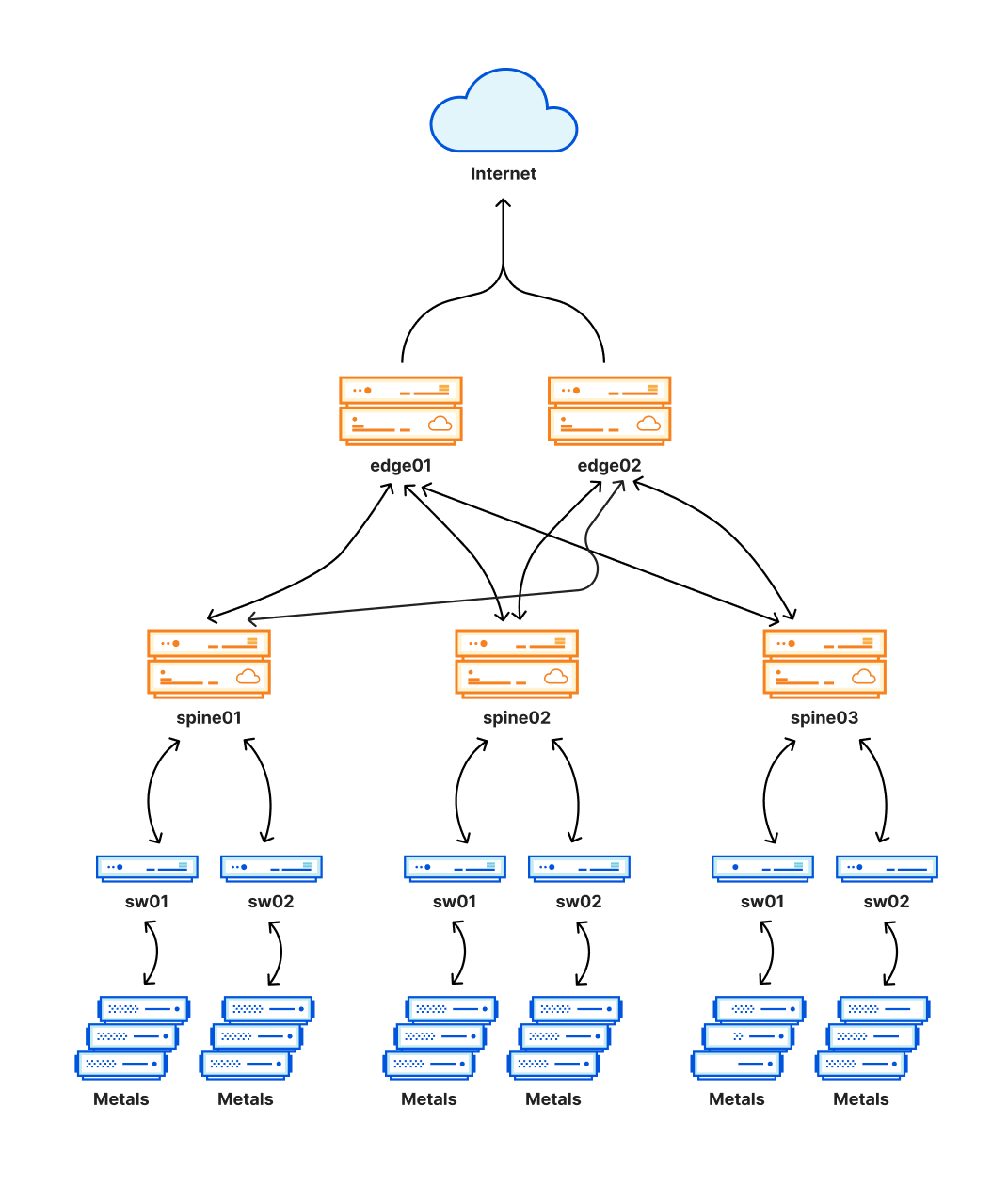
这种新的架构为我们提供了显著的可靠性改进,并且使我们能够在这些地方进行维护而不中断客户流量。由于这些地方同样承担着Cloudflare流量的很大一部分,这里的任何问题都会产生非常广泛的影响。不幸的是,这就是今天发生的事情。
事件的时间线和影响
为了在互联网上能被访问到,像Cloudflare这样的网络利用了一个被叫做BGP的协议。作为该协议的一部分,运营商制定策略,决定哪些前缀(相邻IP地址的集合)被公布给peers(它们连接的其他网络),或从peers接受。
这些策略有单独的组成部分,它们被按顺序进行评估。最终结果是,任何给定的前缀要么被公布,要么不被公布。策略的变化可能意味着以前公布的前缀不再被公布,即所谓的“撤销”。这些IP地址将不能在互联网上到达。
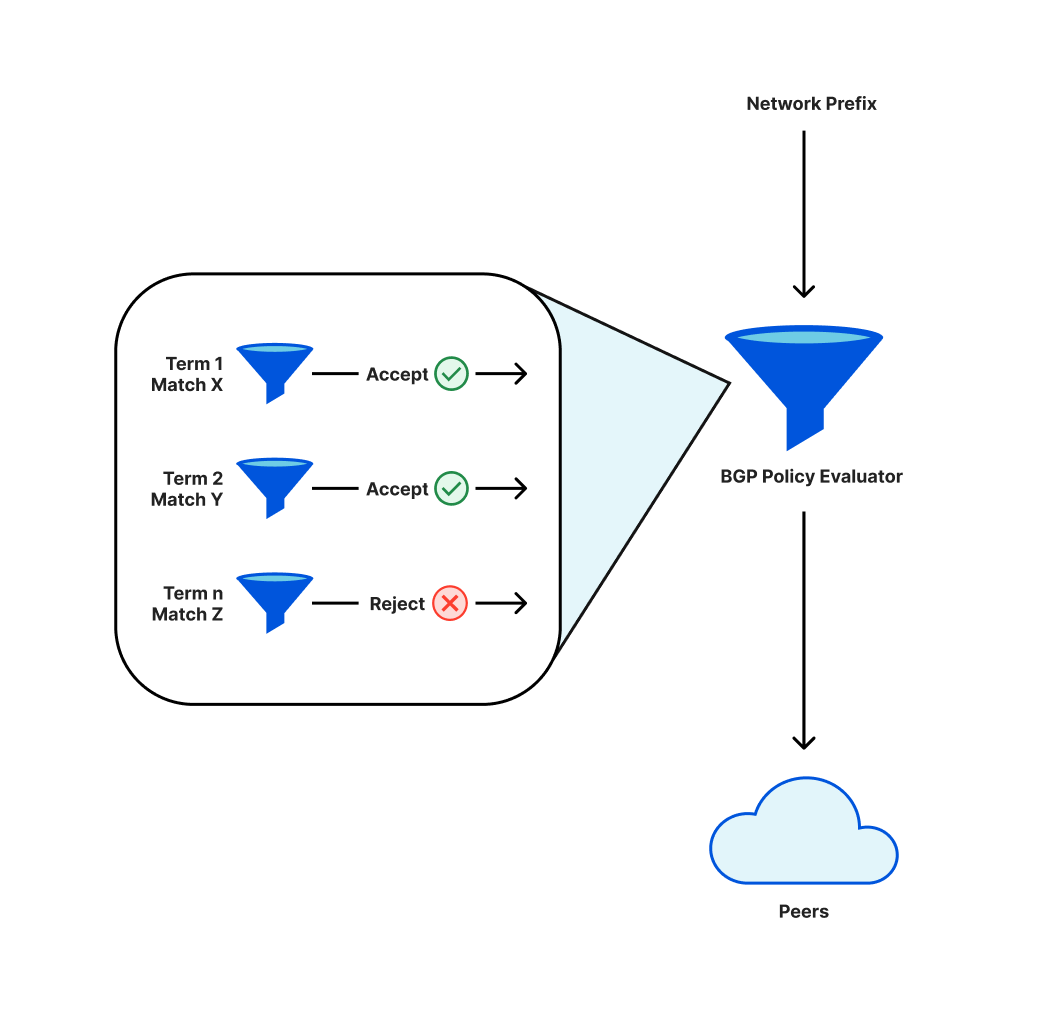
在对我们的前缀公布策略进行修改时,条款的重新排序使得我们撤销了一个关键的前缀子集。
由于这个撤销,Cloudflare的工程师在联系受影响的地点以恢复有问题的变更方面遇到了更多困难。我们有处理此类事件的备份程序,并利用它们来控制受影响的地点。
| 时间 | 事件 |
|---|---|
| 03:56(UTC) | 我们在第一个地点部署了这个变化。我们的所有地点都没有受到该变化的影响,因为这些地点使用的是我们的旧架构。 |
| 06:17 | 变更被部署到我们最繁忙的地点,但不是具有MCP架构的地点。 |
| 06:27 | 推广工作到达了支持MCP的地点,变化被部署到了我们的spines。这时,事件开始了,因为这迅速地使这19个地点宕机。 |
| 06:32 | Cloudflare内部宣布事故发生。 |
| 06:51 | 在路由器上进行了第一次更改,以验证根本原因。 |
| 06:58 | 找到并理解了根本原因。开始恢复有问题的更改。 |
| 07:42 | 最后一项恢复工作已经完成。由于网络工程师们互相走过对方的修改,恢复了之前的恢复,导致问题零星地重新出现,所以这被延迟了。 |
| 09:00 | 事件结束。 |
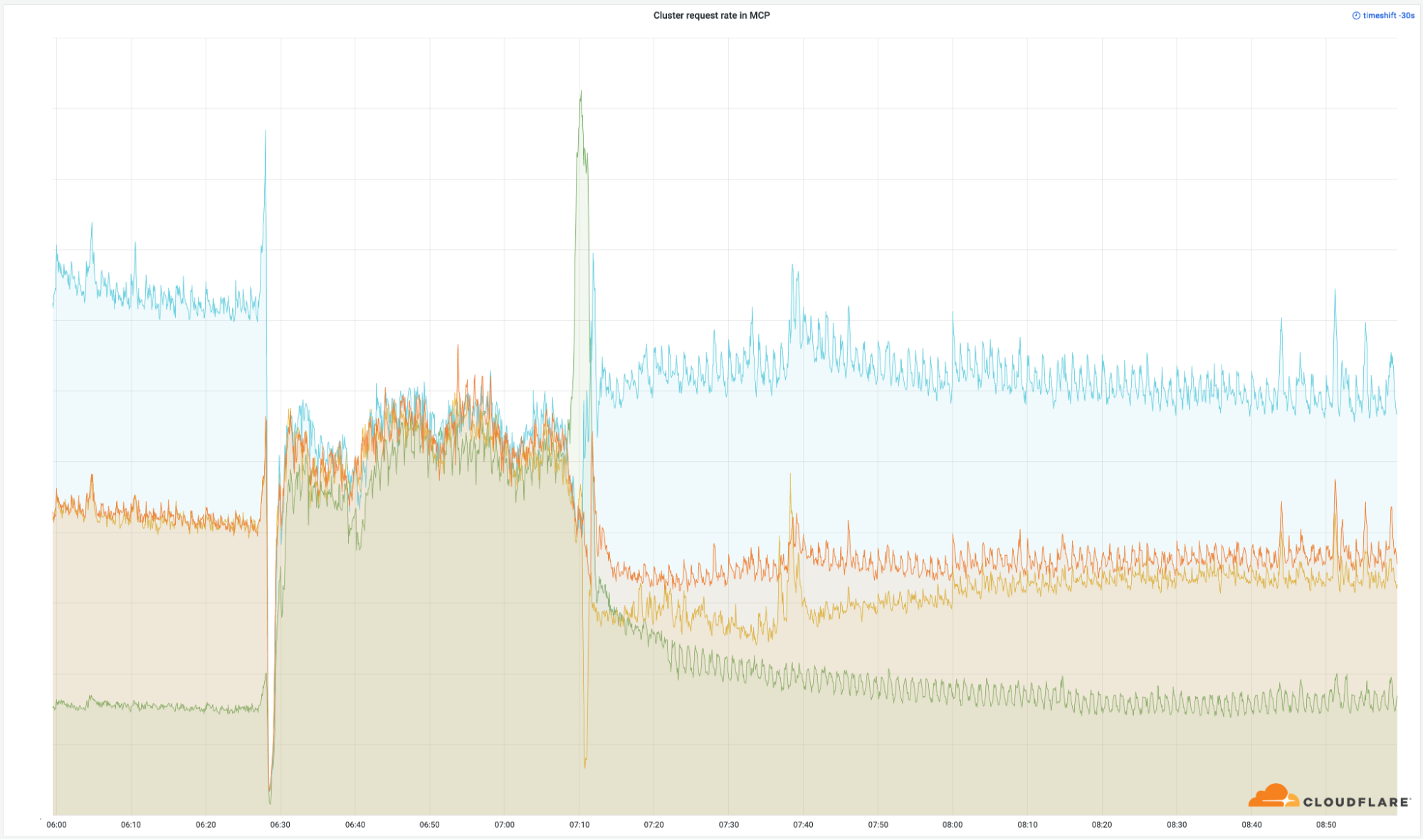
从我们在全球范围内处理的成功的HTTP请求量中可以清楚地看到这些数据中心的重要性。
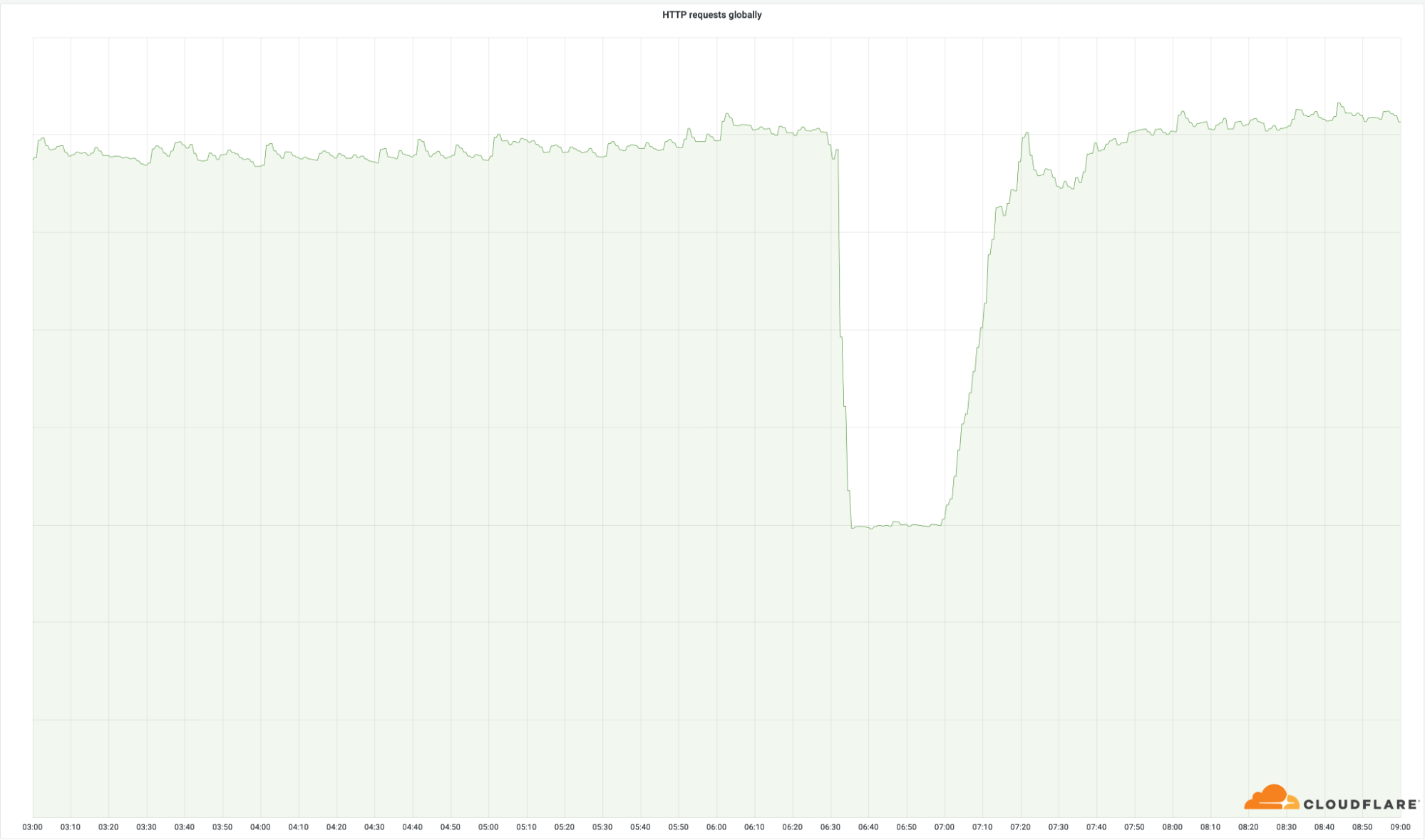
尽管这些地方只占我们整个网络的4%,但中断影响了50%的总请求。在我们的出口带宽中也可以看到同样的情况。
对错误的技术描述以及它是如何发生的
作为我们继续努力使我们的基础设施配置标准化的一部分,我们正在推出一项变化,以使我们公布的前缀的一个子集所附加的BGP社区标准化。具体来说,我们正在为我们的站点-本地前缀添加信息社区。
这些前缀使我们的金属能够相互沟通,并连接到客户的源头。作为Cloudflare变更程序的一部分,我们创建了一个变更请求单,其中包括变更的模拟运行,以及一个逐步推出的程序。在它被允许出去之前,它还被多个工程师进行了同行评审。不幸的是,在这种情况下,这些步骤不够小,无法在我们所有的人都受到影响之前抓住这个错误。
其中一个路由器上的变化看起来是这样的:
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
这是无害的,只是给这些前缀广告增加了一些额外的信息。spines上的变化如下。
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
初步看一下这个差异,可能会让人觉得这个变化是相同的,但不幸的是,情况并非如此。如果我们把注意力集中在差异的一个部分,可能就会明白原因。
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
在这种diff格式中,术语前面的惊叹号表示术语的重新排序。在这种情况下,多个术语被移到上面,两个术语被加到下面。具体来说,4-ADV-SITE-LOCALS和6-ADV-SITE-LOCALS术语从顶部移到底部。这些术语现在在REJECT-THE-REST术语的后面,从名字上可以看出,这个术语是一个明确的拒绝:
term REJECT-THE-REST {
then reject;
}
由于这个术语现在在站点-本地术语之前,我们立即停止宣传我们的站点-本地前缀,取消了我们对所有受影响地点的直接访问,同时也取消了我们的服务器到达原点服务器的能力。
除了无法联系原点之外,删除这些站点本地前缀还导致我们的内部负载平衡系统Multimog(我们的Unimog负载平衡器的一个变种)停止工作,因为它不能再在我们MCP的服务器之间转发请求。这意味着我们在MCP中较小的计算集群收到与我们最大的集群相同的流量,导致较小的集群过载。
补救和后续步骤
这一事件产生了广泛的影响,我们非常重视可用性。我们已经确定了几个需要改进的领域,并将继续努力发现可能导致再次发生的任何其他差距。
以下是我们正在立即开展工作的内容:
处理程序。虽然MCP计划是为了提高可用性,但我们在更新这些数据中心的过程中存在程序上的漏洞,最终导致MCP地点受到了更广泛的影响。虽然我们确实使用了一个交错程序来进行这一变更,但交错政策直到最后一步才包括MCP数据中心。更改程序和自动化需要包括针对MCP的测试和部署程序,以确保没有意外的后果。
架构。不正确的路由器配置使适当的路由无法被公布,使流量无法正常流向我们的基础设施。最终,导致不正确的路由广告的政策声明将被重新设计,以防止无意中的错误排序。
自动化。在我们的自动化套件中,有几个机会可以减轻这一事件所带来的部分或全部影响。主要是,我们将专注于自动化改进,为网络配置的推出执行改进的错开政策,并提供自动 “提交-确认 “回滚。前者将大大减少整体影响,后者将大大减少事件中的解决时间。
结论
尽管Cloudflare对我们的MCP设计进行了大量投资,以提高服务的可用性,但这次非常痛苦的事件,我们显然没有达到客户的期望。我们对我们的客户和所有在故障期间无法访问互联网属性的用户所受到的干扰深表遗憾。我们已经开始着手进行上述改革,并将继续努力确保这种情况不会再次发生。
References
https://blog.cloudflare.com/cloudflare-outage-on-june-21-2022