SQL
SQL概述
SQL的特点
- 综合统一:集DQ、DDL、DML、DCL于一体
- 高度非过程化:不用考虑如何实现,只需提出“做什么”,不关心“怎么做”
- 面向集合的操作方式:查询、插入、删除、更新操作对象及结果都是集合
- 以同一种语法结构提供两种使用方法:可交互式和嵌入式使用
- 以简捷的自然语言实现对数据库的定义、操作和控制功能:定义了少量的关键字实现对数据库的定义、操纵和控制功能
SQL所使用的动词(核心功能)
| SQL功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE, DROP, ALTER |
| 数据操作 | INSERT, UPDATE, DELETE |
| 数据控制 | GRANT, REVOKE |
数据定义
SQL的数据定义语句
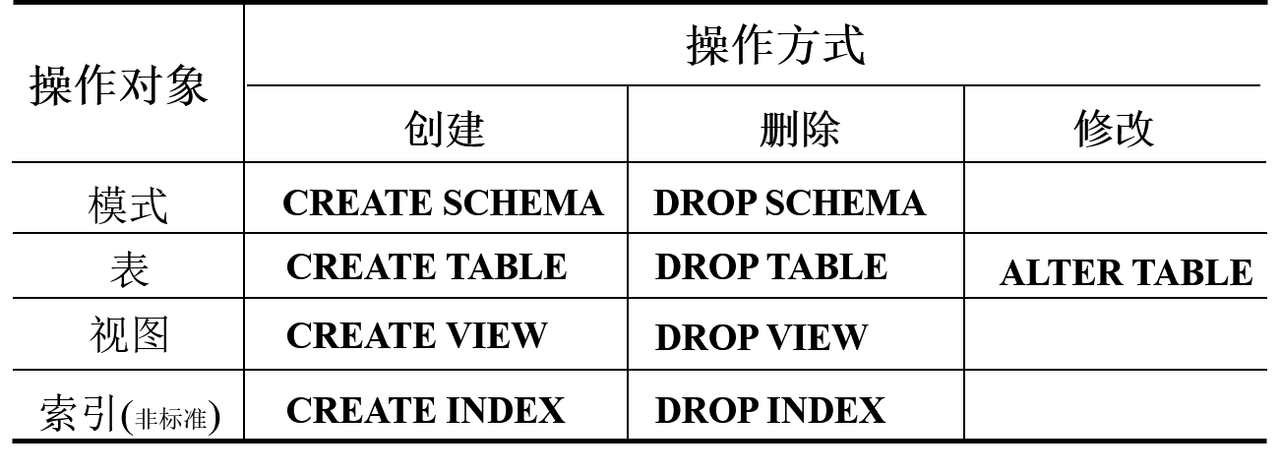
SQL中的数据类型
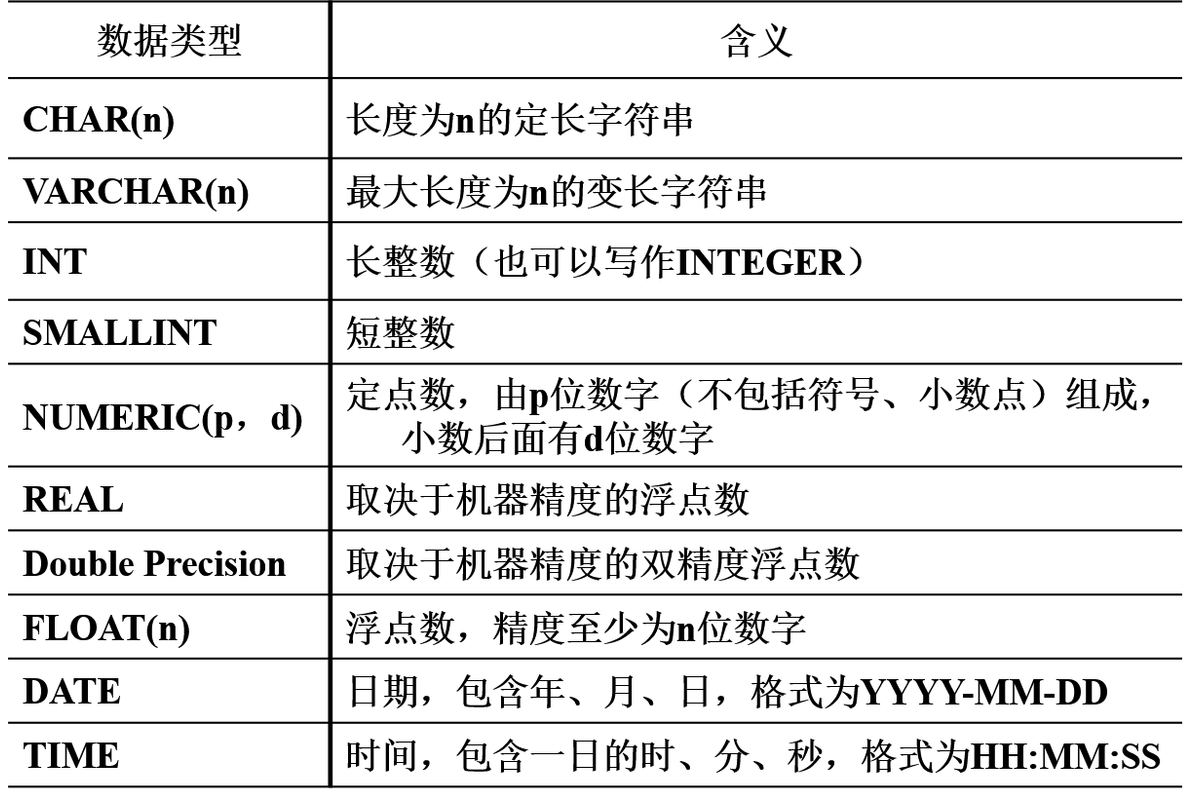
基本表的定义
创建基本表
CREATE TABLE <表名>
( <列名> <数据类型>[<列级完整性约束条件>]
[, <列名> <数据类型>[<列级完整性约束条件>] ] …
[, <表级完整性约束条件> ] ) ;
- 常用的完整性约束
- 主码约束:PRIMARY KEY (<列名1>, <列名2>,…)
- 非空值约束:NOT NULL
- 唯一性约束:UNIQUE
- 参照完整性约束:FOREIGN KEY (<列名>) REFERENCES <表名>(<列名>)
- 一般性约束:CHECK(<谓词>)

删除基本表
DROP TABLE <表名> [RESTRICT|CASCADE];
RESTRICT:删除表是有限制的:
- 欲删除的基本表不能被其他表的约束所引用
- 如果存在依赖该表的对象,则此表不能被删除
CASCADE:级联,删除该表没有限制。 在删除基本表的同时,相关的依赖对象一起删除
⚠️缺省是RESTRICT
修改基本表
ALTER TABLE <表名>
[ADD[COLUMN] <新列名> <数据类型> [ 完整性约束 ]]
[ADD <表级完整性约束>]
[DROP [ COLUMN ] <列名> [CASCADE|RESTRICT]]
[DROP CONSTRAINT<完整性约束名>[RESTRICT|CASCADE]]
[ALTER COLUMN<列名> <数据类型>];
- <表名>:要修改的基本表
- ADD子句:增加新列和新的完整性约束条件
- DROP COLUMN子句: 用于删除表中的列
- DROP CONSTRAINT子句:删除指定的完整性约束条件
- ALTER COLUMN子句:用于修改列名和数据类型
⚠️删除属性列
- 间接删除(由DBA或表的Owner操作)
- 把表中要保留的列及其内容复制到一个新表中
- 删除原表
- 再将新表重命名为原表名
- 直接删除(SQL-99)
例:ALTER TABLE S Drop Scome ;
索引的定义
索引的分类
- 普通索引(Normal Index):一个索引值可能对应多条存储记录
- 单一索引(Unique Index):每一个索引值只对应唯一的数据记录。
- 聚簇索引(Cluster Index):基本表按照索引项顺序组织存储。
- 一个基本表上最多只能建立一个聚簇索引
- 在最经常查询的列上建立聚簇索引
- 经常更新的列不宜建立聚簇索引
创建索引
CREATE [UNIQUE] | [CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);
- 用<表名>指定要建索引的基本表名字
- 索引可以建立在该表的一列或多列上,各列名之间用逗号分隔
- 用<次序>指定索引值的排列次序。升序:ASC,降序:DESC,缺省值:ASC
- UNIQUE表明此索引的每一个索引值对应唯一的数据记录
- CLUSTER表示要建立的索引是聚簇索引
例7: 为学生表S和选课表SC建立索引。其中S表按学号升序建唯一索引,按年龄降序建立普通索引,SC表按学号升序和课程号降序建唯一索引。
CREATE UNIQUE INDEX Stusno ON S (Sno);
CREATE INDEX Stusage ON S (Sage DESC);
CREATE UNIQUE INDEX SCno
ON SC(Sno ASC, Cno DESC);
删除索引
DROP INDEX <索引名>;
修改索引
ALTER INDEX <旧索引名> RENAME TO <新索引名>;
数据查询
查询语法
SELECT [ALL | DISTINCT] <目标列表达式> [,<目标列表达式>] … FROM <表名或视图名>[, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <列名2> [ ASC | DESC ] ] ;
单表查询
目标列为表达式的查询
SELECT Sname, 1996 - Sage FROM Student ;使用别名改变查询结果的列标题
SELECT Sname NAME, 'Year of Birth:' BIRTH, 1996 - Sage BIRTHYEAR, ISLOWER ( Sdept ) DEPARTMENT消除结果中重复的行
SELECT **DISTINCT** Sno FROM SC ;限定查询范围
查询条件 谓 词 比 较 = , < , > , <= , >= , <> , != , !> , !< ; NOT + 上述比较符 确定范围 BETWEEN … AND … , NOT BETWEEN … AND … 确定集合 IN, NOT IN 字符匹配 LIKE, NOT LIKE 空 值 IS NULL, IS NOT NULL 多重条件 AND, OR - 确定范围
SELECT Sname, Sdept, Sage FROM Student WHERE Sage BETWEEN 20 AND 23 ;确定集合
SELECT Sname, Ssex FROM Student WHERE Sdept NOT IN ('IS', 'MA', 'CS') ;字符串匹配
[NOT] LIKE ‘<匹配模板>’ [ESCAPE ‘<换码字符>’]%(百分号):代表任意长度(可以为0)的字符串。
例:a%b表示以a开头,以b结尾的任意长度的字符串。如acb,addgb,ab 等都满足该匹配串。
_(下横线):代表任意单个字符。
例:a_b表示以a开头,以b结尾的长度为3的任意字符串。如acb,afb等都满足该匹配串,一个汉字两个下横线
当要查询的字符串本身就含有 % 或 _ 时,要使用
ESCAPE '<换码字符>'短语对通配符进行转义。SELECT Cno, Ccredit FROM Course WHERE Cname LIKE 'DB\_Design' ESCAPE '\' ; ;转义符‘\’表示模板中出现在其后的第一个字符不再是通配符,而是字符本身。
涉及空值的查询
使用谓词 IS NULL 或 IS NOT NULL,“IS NULL” 不能用 “= NULL” 代替!
排序输出
ORDER BY- 升序:ASC ,排列为空值的元组最后显示 (空值最大)
- 降序:DESC
聚集函数
- 计数 COUNT (使用 DISTINCT 避免重复计数)
- 计算总和 SUM
- 计算平均值 AVG
- 求最大值 MAX
- 求最小值 MIN
[ GROUP BY <列名1>[, 列名2…] [ HAVING <条件表达式> ] ]未对查询结果分组,集函数将作用于整个查询结果
对查询结果分组后,集函数将分别作用于每个组
⚠️使用GROUP BY子句后,SELECT子句的列名表中只能出现分组属性和集函数
集函数只能用于SELECT子句和 HAVING短语之中,而绝对不能出现在 WHERE 子句中(WHERE子句执行过程是对记录逐一检验,并没有结果集,故无法施加集函数)。

连接查询
等值连接、自然连接
SELECT子句和WHERE子句中出现的两个同名属性前要加所属表名作前辍以区别,无同名则可省前辍。
自身连接
需要给表起别名以示区别,由于所有的属性名都是同名属性, 因此必须使用别名前缀
外连接 Outer Join
- 左外连接:在连接的右边出现空行
- 右外连接:在连接的左边出现空行
- 左右外链接:在连接的左右出现空行
Note
连接类型
- 内连接(INNER JOIN)
- 左外连接(LEFT OUTER JOIN)
- 右外连接(RIGHT OUTER JOIN)
- 全外连接(FULL OUTER JOIN)
嵌套查询
带有IN谓词的子查询
带有比较运算符的子查询
- ⚠️特别注意:子查询一定要跟在比较符之后!
带有ANY(SOME)或ALL谓词的查询

带有EXISTS谓词的子查询
EXISTS谓词的意义:
- 是存在量词在SQL中的应用
- 带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”
- 若内层查询结果非空,则返回真值
- 若内层查询结果为空,则返回假值
- 由EXISTS引出的子查询,其目标列表达式通常都用*:因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义



嵌套查询小结
嵌套查询分为相关子查询和不相关子查询
- 不相关子查询的执行不依赖于父查询的任何条件
- 语句上不出现父查询中的属性
- 执行上首先运行,且只运行一次即可得到确定的结果
- 子查询的结果集将作为父查询的条件使用
- 相关子查询的执行与父查询的当前值相关
- 语句上出现父查询中的属性
- 执行上父查询的当前值会作为子查询的条件
- 子查询的属性不会出现在父查询的输出上(Select 子句)
- 子查询不能使用ORDER BY子句, ORDER BY子句只能对最终结果排序
集合查询
将两个SELECT-FROM-WHERE查询块用集合操作命令联结起来的查询
集合操作命令
- 并操作(UNION)
- 交操作(INTERSECT)
- 差操作(EXCEPT)
语句形式
<查询块>
UNION [ALL] | INTERSECT | EXCEPT
<查询块> ;

数据更新
插入数据
插入单个元组

插入子查询结果
INSERT
INTO <表名> [(<属性列1> [, <属性列2>… )]
子查询 ;
修改数据

删除数据
DELETE
FROM <表名>
[WHERE <条件>] ;
注意事项
DBMS在执行插入、删除、修改语句时必须保证数据库的完整性和一致性。